Séries temporelles en tidy
State of the R
24-28/08/2020
Format tidy
library(tidyverse)
library(tsibble) # Handling time series tibble
library(fable)Exemple de série de températures
weather <- nycflights13::weather %>%
dplyr::select(origin, time_hour, temp, humid, precip)
weather## # A tibble: 26,115 x 5
## origin time_hour temp humid precip
## <chr> <dttm> <dbl> <dbl> <dbl>
## 1 EWR 2013-01-01 01:00:00 39.0 59.4 0
## 2 EWR 2013-01-01 02:00:00 39.0 61.6 0
## 3 EWR 2013-01-01 03:00:00 39.0 64.4 0
## 4 EWR 2013-01-01 04:00:00 39.9 62.2 0
## 5 EWR 2013-01-01 05:00:00 39.0 64.4 0
## 6 EWR 2013-01-01 06:00:00 37.9 67.2 0
## 7 EWR 2013-01-01 07:00:00 39.0 64.4 0
## 8 EWR 2013-01-01 08:00:00 39.9 62.2 0
## 9 EWR 2013-01-01 09:00:00 39.9 62.2 0
## 10 EWR 2013-01-01 10:00:00 41 59.6 0
## # … with 26,105 more rowsOn a une colonne temporelle et différentes colonnes d’attributs. On s’intéresse aux températures de trois aéroports.
ggplot(weather) +
aes(y = temp, x = time_hour) +
geom_path(aes(color = origin))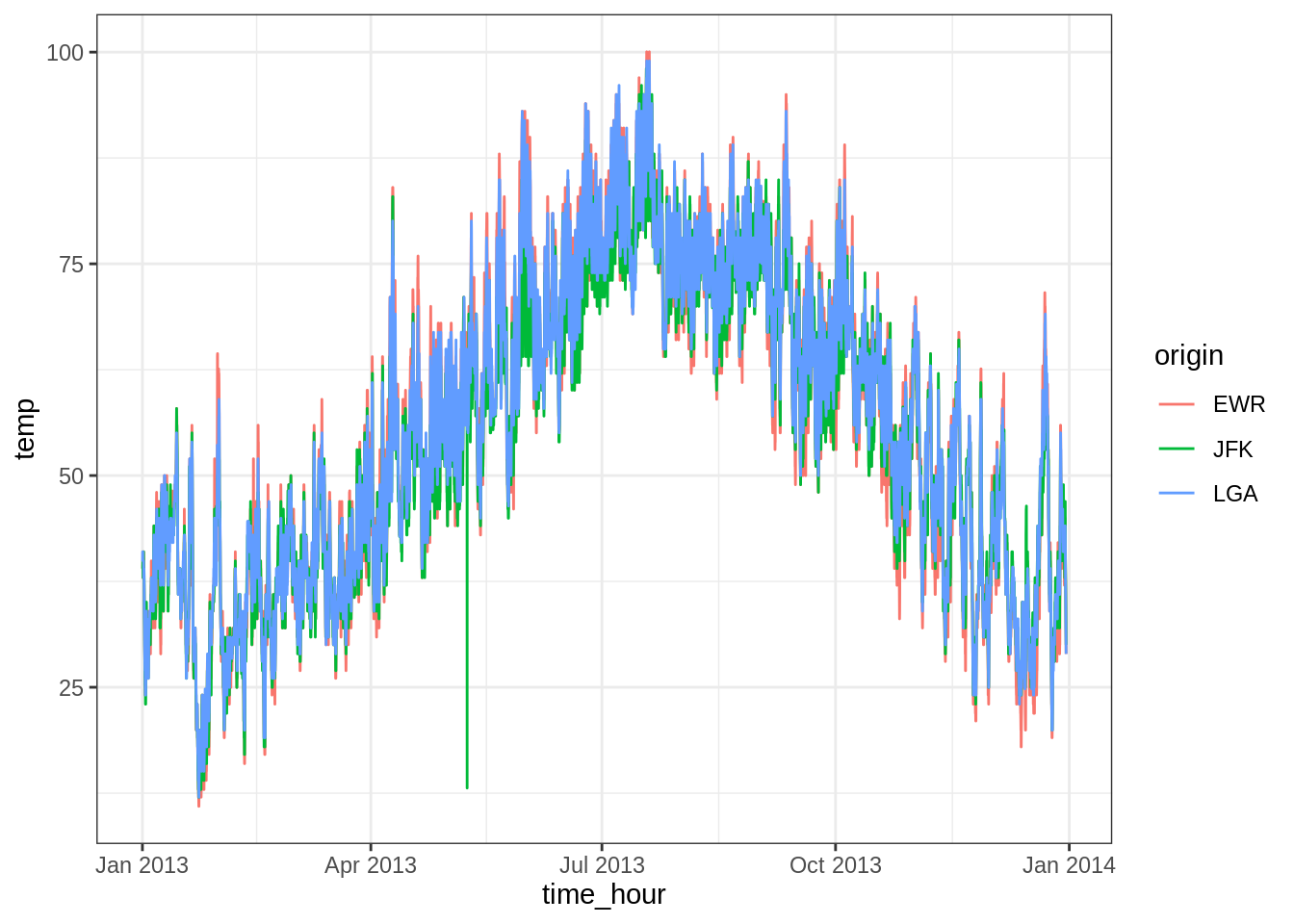
L’idée de tsibble est de créer un tableaux de série(s) temporelle(s). À partir d’un tibble, on utilisera la fonction as_tsibble. Cette fonction permet de traiter “spécialement” la colonne date.
Important : Dans un tsibble, il ne peut pas y avoir deux dates identiques. Du coup, ici, comme des dates sont répétées pour différents aéroports, on spécifiera que la colonne correspondante (origin) est une clé de référence.
weather_tsbl <- as_tsibble(x = weather, # Tableau
key = origin, # Clé d'identification
index = time_hour, # Date
regular = TRUE ) # On spécifie que c'est régulier
weather_tsbl## # A tsibble: 26,115 x 5 [1h] <America/New_York>
## # Key: origin [3]
## origin time_hour temp humid precip
## <chr> <dttm> <dbl> <dbl> <dbl>
## 1 EWR 2013-01-01 01:00:00 39.0 59.4 0
## 2 EWR 2013-01-01 02:00:00 39.0 61.6 0
## 3 EWR 2013-01-01 03:00:00 39.0 64.4 0
## 4 EWR 2013-01-01 04:00:00 39.9 62.2 0
## 5 EWR 2013-01-01 05:00:00 39.0 64.4 0
## 6 EWR 2013-01-01 06:00:00 37.9 67.2 0
## 7 EWR 2013-01-01 07:00:00 39.0 64.4 0
## 8 EWR 2013-01-01 08:00:00 39.9 62.2 0
## 9 EWR 2013-01-01 09:00:00 39.9 62.2 0
## 10 EWR 2013-01-01 10:00:00 41 59.6 0
## # … with 26,105 more rowsComme l’espacement temporel est régulier, celui-ci est indiqué entre crochets ([1h]) lors de l’affichage.
Groupement et résumé par période
Par défaut, il y a un groupement par l’index (ici chaque heure). Par exemple, le code suivant donne la moyenne par heure (tous aéroports confondus).
weather_tsbl %>%
summarise(
temp_mean = mean(temp, na.rm = TRUE),
)## # A tsibble: 8,714 x 2 [1h] <America/New_York>
## time_hour temp_mean
## <dttm> <dbl>
## 1 2013-01-01 01:00:00 39.3
## 2 2013-01-01 02:00:00 39.7
## 3 2013-01-01 03:00:00 40.0
## 4 2013-01-01 04:00:00 40.3
## 5 2013-01-01 05:00:00 39.3
## 6 2013-01-01 06:00:00 38.6
## 7 2013-01-01 07:00:00 39.3
## 8 2013-01-01 08:00:00 39.9
## 9 2013-01-01 09:00:00 39.9
## 10 2013-01-01 10:00:00 40.6
## # … with 8,704 more rowsOn peut toujours grouper par la clé (les aéroports).
weather_tsbl %>%
group_by_key() %>% # Equivalent à group_by(origin)
summarise(temp_mean = mean(temp, na.rm = TRUE))## # A tsibble: 26,115 x 3 [1h] <America/New_York>
## # Key: origin [3]
## origin time_hour temp_mean
## <chr> <dttm> <dbl>
## 1 EWR 2013-01-01 01:00:00 39.0
## 2 EWR 2013-01-01 02:00:00 39.0
## 3 EWR 2013-01-01 03:00:00 39.0
## 4 EWR 2013-01-01 04:00:00 39.9
## 5 EWR 2013-01-01 05:00:00 39.0
## 6 EWR 2013-01-01 06:00:00 37.9
## 7 EWR 2013-01-01 07:00:00 39.0
## 8 EWR 2013-01-01 08:00:00 39.9
## 9 EWR 2013-01-01 09:00:00 39.9
## 10 EWR 2013-01-01 10:00:00 41
## # … with 26,105 more rowsEvidemment, on peut vouloir faire des résumés sur un période donnée. Pour ça, il faut utiliser la fonction index_by et la fonction de regroupement adaptée (voir help(index_by)).
weather_tsbl %>%
group_by_key() %>% # Equivalent à group_by(origin)
index_by(week = ~ yearweek(.)) %>% # Voir help(index_by) pour les périodes possibles
summarise(mean_temp = mean(temp, na.rm = TRUE)) %>%
ggplot(aes(x = week, y = mean_temp)) +
geom_path(aes(color = origin))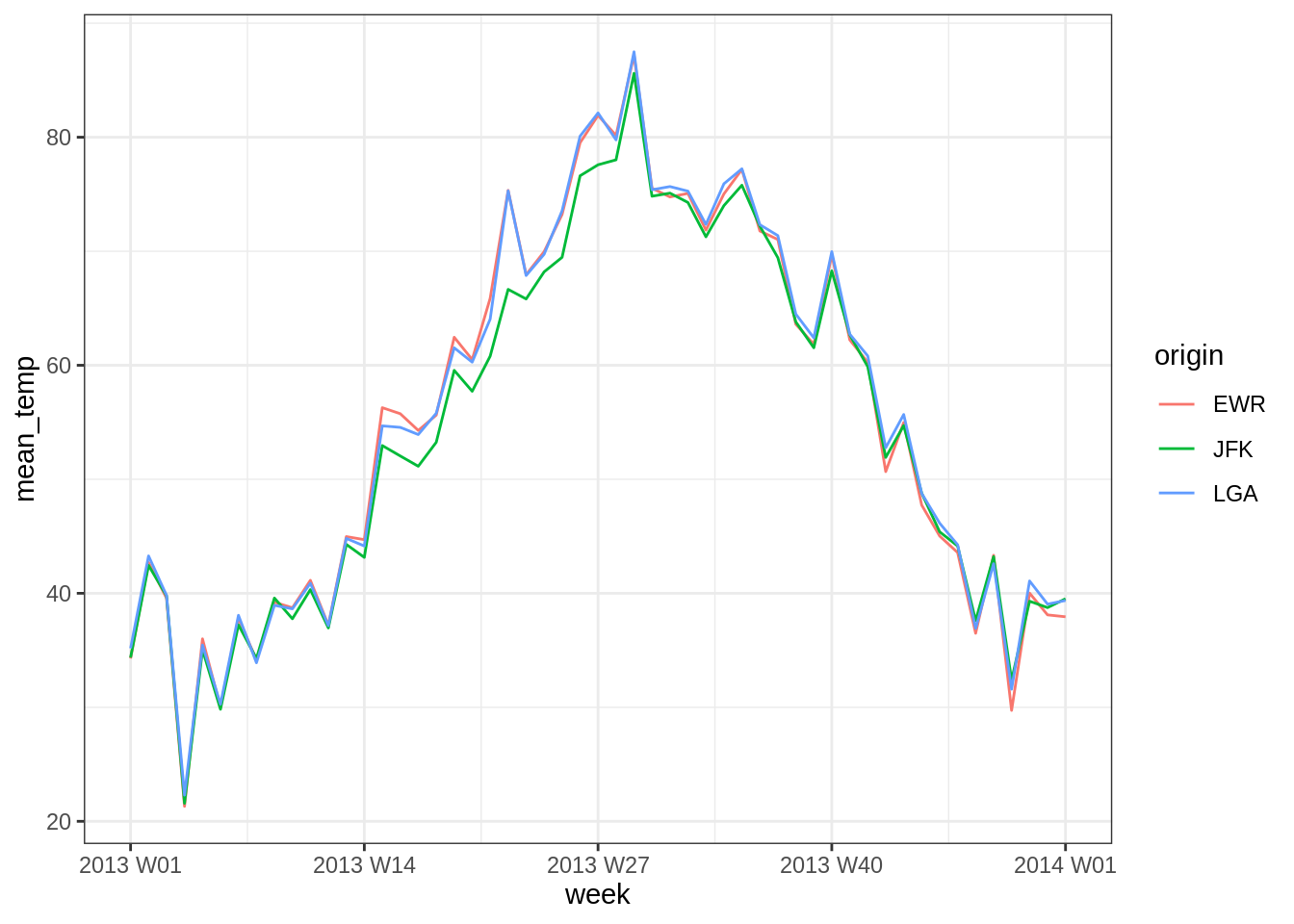
Filtrage par période
La fonction filter_index permet de filtrer sur les périodes.
Par exemple, si on s’intéresse spécifiquement aux mois d’Octobre et Novembre:
weather_tsbl %>%
filter_index("2013-10" ~ "2013-11") # Voir help(filter_index) pour ## # A tsibble: 2,212 x 5 [1h] <America/New_York>
## # Key: origin [3]
## origin time_hour temp humid precip
## <chr> <dttm> <dbl> <dbl> <dbl>
## 1 EWR 2013-10-01 00:00:00 59 83.3 0
## 2 EWR 2013-10-01 01:00:00 57.9 86.6 0
## 3 EWR 2013-10-01 02:00:00 57.9 83.8 0
## 4 EWR 2013-10-01 03:00:00 57.0 83.2 0
## 5 EWR 2013-10-01 04:00:00 55.9 86.5 0
## 6 EWR 2013-10-01 05:00:00 53.1 89.3 0
## 7 EWR 2013-10-01 06:00:00 55.0 89.4 0
## 8 EWR 2013-10-01 07:00:00 57.0 86.6 0
## 9 EWR 2013-10-01 08:00:00 63.0 70.1 0
## 10 EWR 2013-10-01 09:00:00 69.1 58.6 0
## # … with 2,202 more rows# la spécification de période (notamment multiples périodes non connexes)Moyenne mobile
Si on veut lisser, on a les fonctions du package slider (qui remplace les fonctions de tsibble dépréciées).
Par exemple, si on veut lisser sur 101 heures (50 avant, 50 après).
library(slider) ##
## Attaching package: 'slider'## The following objects are masked from 'package:tsibble':
##
## pslide, pslide_chr, pslide_dbl, pslide_dfc, pslide_dfr, pslide_int,
## pslide_lgl, slide, slide_chr, slide_dbl, slide_dfc, slide_dfr,
## slide_int, slide_lgl, slide2, slide2_chr, slide2_dbl, slide2_dfc,
## slide2_dfr, slide2_int, slide2_lgl# Lissage sur 10h
weather_tsbl %>%
group_by_key() %>% # Groupement par aeroport
mutate(smoothed_temp = slide_dbl(temp, .f = mean,
.before = 50, .after = 50)) %>%
ggplot() +
aes(x = time_hour, y = smoothed_temp, color = origin)
geom_path()## geom_path: lineend = butt, linejoin = round, linemitre = 10, arrow = NULL, na.rm = FALSE
## stat_identity: na.rm = FALSE
## position_identityPrédiction avec modèles ETS ou ARIMA : package fable
tourism_melb <- tourism %>%
filter(Region == "Melbourne")
tourism_melb %>%
ggplot(aes(x = Quarter, y = Trips)) +
geom_path(aes(color = Purpose)) 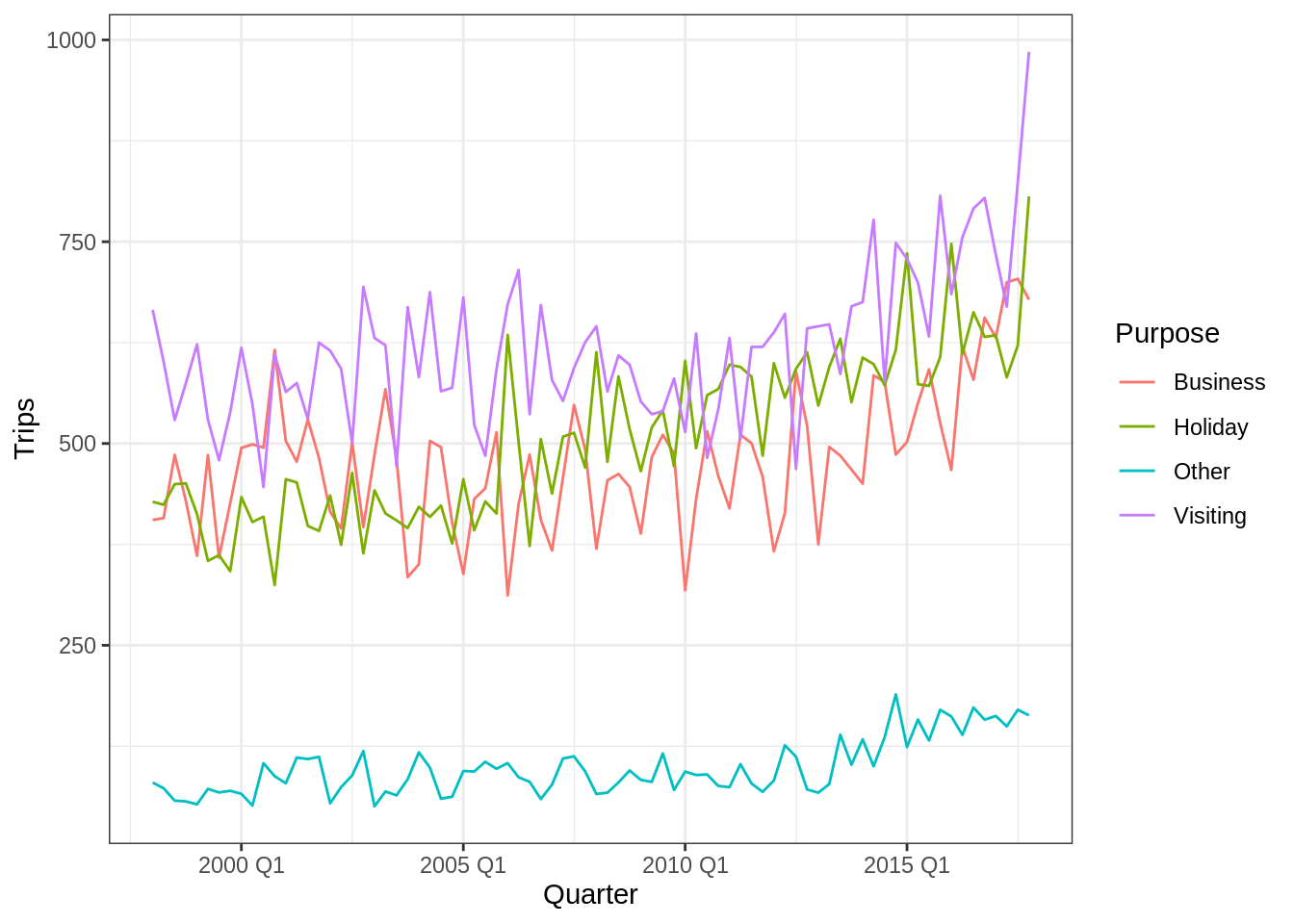
On peut ajuster différents modèles de séries temporelles. Cet ajustement est fait via la fonction model du package fabletools. L’objet résultant est un mable (tableau de modèles).
fitted_mable <- tourism_melb %>%
fabletools::model(
ets = ETS(Trips ~ trend("A") + season("A", period = 4)),
arima = ARIMA(Trips)
)## Warning: 4 errors (1 unique) encountered for arima
## [4] The `feasts` package must be installed to use this functionality. It can be installed with install.packages("feasts")fitted_mable## # A mable: 4 x 5
## # Key: Region, State, Purpose [4]
## Region State Purpose ets arima
## <chr> <chr> <chr> <model> <model>
## 1 Melbourne Victoria Business <ETS(A,A,A)> <NULL model>
## 2 Melbourne Victoria Holiday <ETS(M,A,A)> <NULL model>
## 3 Melbourne Victoria Other <ETS(A,A,A)> <NULL model>
## 4 Melbourne Victoria Visiting <ETS(M,A,A)> <NULL model>Pour chaque modèle, on peut analyser les coefficients :
fitted_mable %>%
dplyr::select(Region, State, Purpose, ets) %>%
coef()## # A tibble: 32 x 6
## Region State Purpose .model term estimate
## <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 Melbourne Victoria Business ets alpha 0.235
## 2 Melbourne Victoria Business ets beta 0.0224
## 3 Melbourne Victoria Business ets gamma 0.000100
## 4 Melbourne Victoria Business ets l 450.
## 5 Melbourne Victoria Business ets b 5.44
## 6 Melbourne Victoria Business ets s0 1.50
## 7 Melbourne Victoria Business ets s1 37.9
## 8 Melbourne Victoria Business ets s2 19.9
## 9 Melbourne Victoria Holiday ets alpha 0.0308
## 10 Melbourne Victoria Holiday ets beta 0.0308
## # … with 22 more rowsOn peut représenter les prédictions par le modèle :
fitted_mable %>%
augment() %>%
dplyr::select(-Region, -State, -.resid) %>%
rename(.observations = Trips) %>%
gather(-Purpose, -.model, -Quarter, key = ".method", value = "value") %>%
ggplot(aes(x = Quarter, y = value, color = .method)) +
geom_path() +
facet_grid(.model ~ Purpose)## Warning: Removed 160 row(s) containing missing values (geom_path).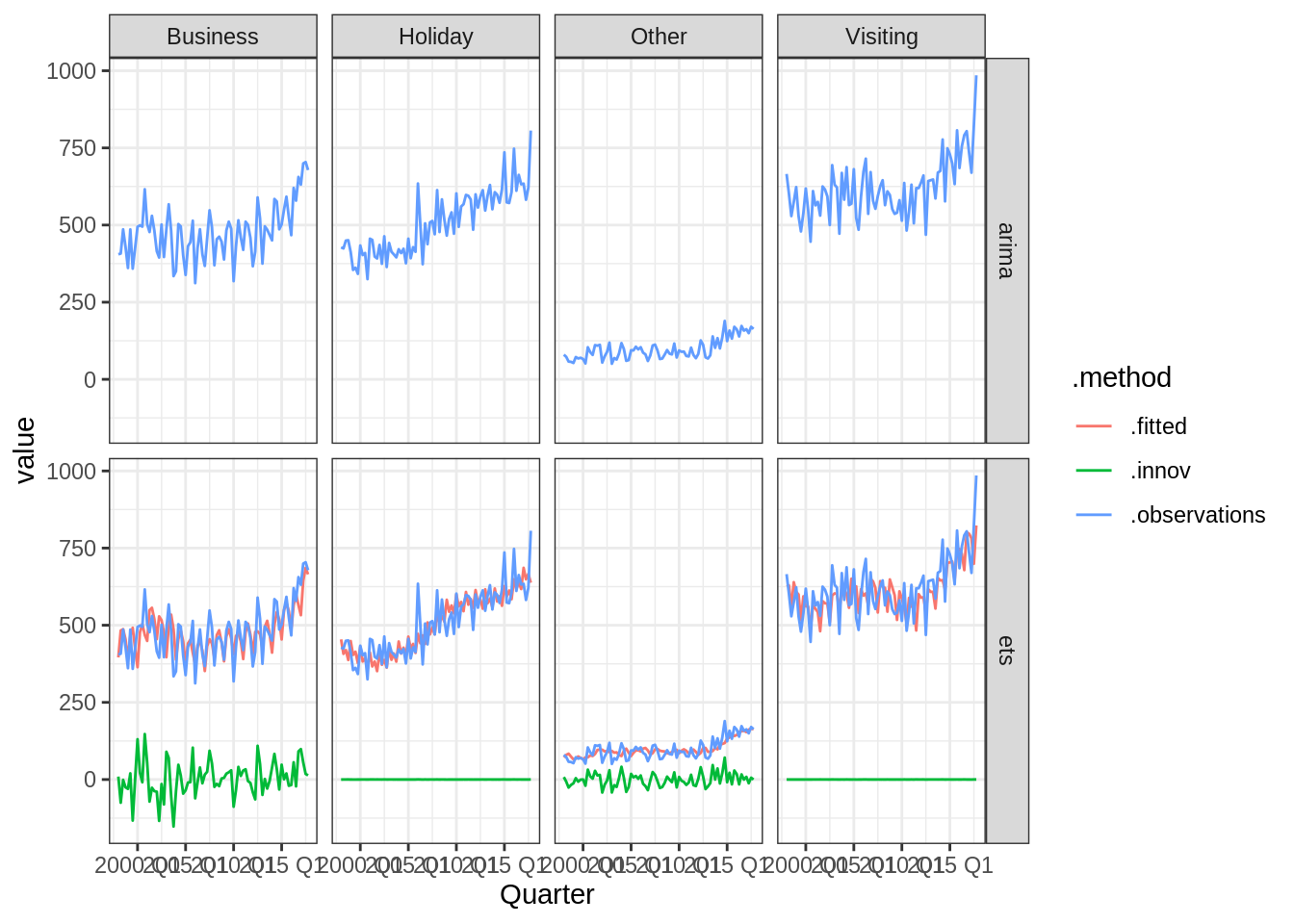
ou encore les résidus (on remarquera ici qu’il semble y avoir une incohérence entre les prédictions ci-dessus et le calcul des résidus ci-dessous).
fitted_mable %>%
augment() %>%
ggplot(aes(x = Quarter, y = .resid)) +
geom_path() +
facet_wrap(~ Purpose + .model, scales = "free_y")## Warning: Removed 80 row(s) containing missing values (geom_path).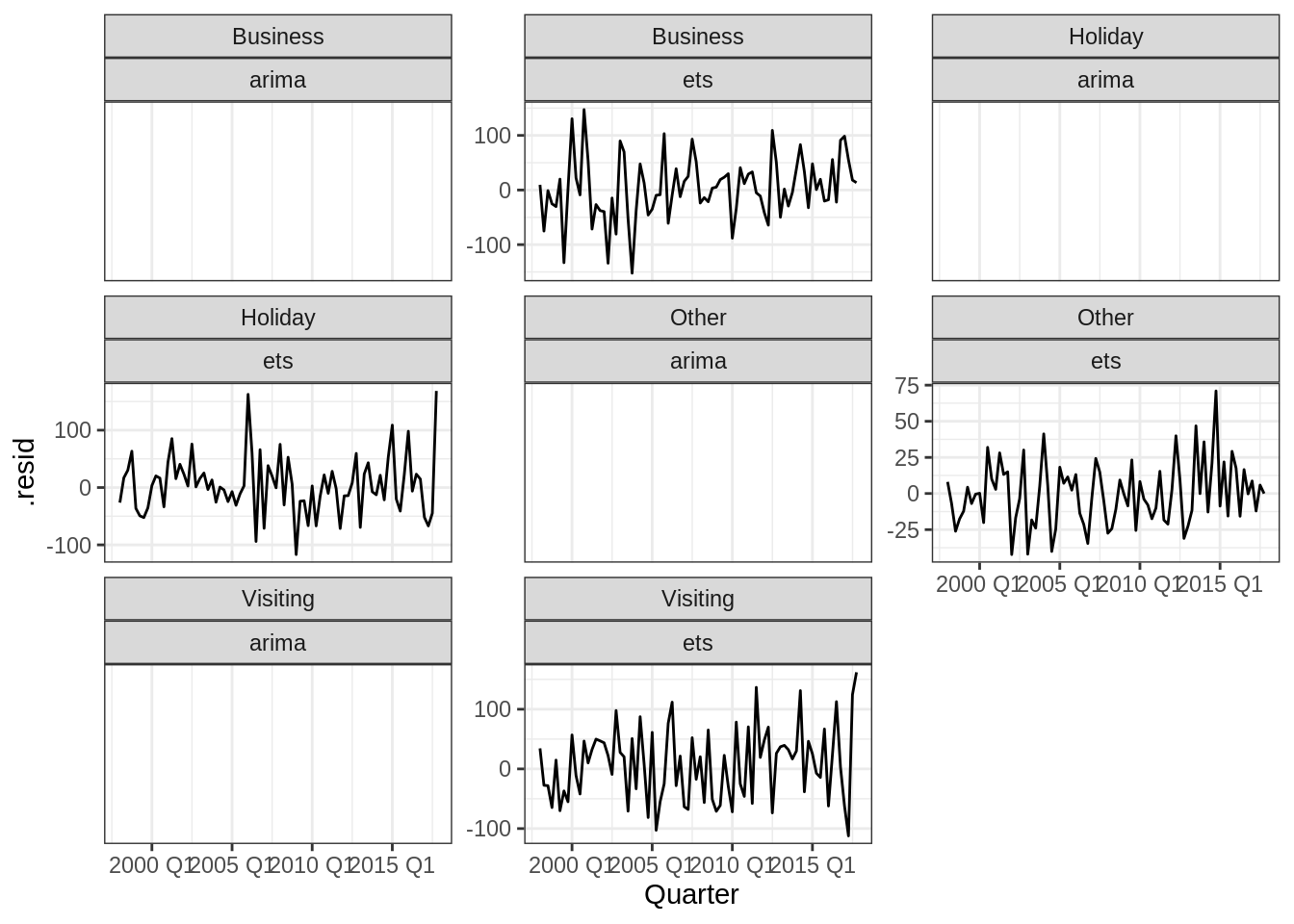
Enfin, on peut créer un tableau de prédiction (ou fable):
forecast_fable <- fitted_mable %>%
forecast(h = "5 years")
forecast_fable## # A fable: 160 x 7 [1Q]
## # Key: Region, State, Purpose, .model [8]
## Region State Purpose .model Quarter Trips .mean
## <chr> <chr> <chr> <chr> <qtr> <dist> <dbl>
## 1 Melbourne Victoria Business ets 2018 Q1 N(619, 3533) 619.
## 2 Melbourne Victoria Business ets 2018 Q2 N(709, 3766) 709.
## 3 Melbourne Victoria Business ets 2018 Q3 N(738, 4042) 738.
## 4 Melbourne Victoria Business ets 2018 Q4 N(713, 4364) 713.
## 5 Melbourne Victoria Business ets 2019 Q1 N(664, 4735) 664.
## 6 Melbourne Victoria Business ets 2019 Q2 N(755, 5159) 755.
## 7 Melbourne Victoria Business ets 2019 Q3 N(784, 5640) 784.
## 8 Melbourne Victoria Business ets 2019 Q4 N(759, 6181) 759.
## 9 Melbourne Victoria Business ets 2020 Q1 N(710, 6786) 710.
## 10 Melbourne Victoria Business ets 2020 Q2 N(800, 7458) 800.
## # … with 150 more rowsOn notera que la prédiction est de la classe distribution du package distributional (voir le travail d’Antoine). On peut ainsi utiliser les fonctionnalités de ce package pour obtenir les intervalles de confiance.
forecast_fable %>%
hilo(level = c(70, 95))## # A tsibble: 160 x 9 [1Q]
## # Key: Region, State, Purpose, .model [8]
## Region State Purpose .model Quarter Trips .mean `70%`
## <chr> <chr> <chr> <chr> <qtr> <dist> <dbl> <hilo>
## 1 Melbo… Vict… Busine… ets 2018 Q1 N(619, 3533) 619. [556.9562, 680.1666]70
## 2 Melbo… Vict… Busine… ets 2018 Q2 N(709, 3766) 709. [645.4872, 772.6996]70
## 3 Melbo… Vict… Busine… ets 2018 Q3 N(738, 4042) 738. [672.5729, 804.3587]70
## 4 Melbo… Vict… Busine… ets 2018 Q4 N(713, 4364) 713. [644.9799, 781.9091]70
## 5 Melbo… Vict… Busine… ets 2019 Q1 N(664, 4735) 664. [592.7150, 735.3526]70
## 6 Melbo… Vict… Busine… ets 2019 Q2 N(755, 5159) 755. [680.1205, 829.0112]70
## 7 Melbo… Vict… Busine… ets 2019 Q3 N(784, 5640) 784. [706.1009, 861.7756]70
## 8 Melbo… Vict… Busine… ets 2019 Q4 N(759, 6181) 759. [677.4317, 840.4021]70
## 9 Melbo… Vict… Busine… ets 2020 Q1 N(710, 6786) 710. [624.1262, 794.8863]70
## 10 Melbo… Vict… Busine… ets 2020 Q2 N(800, 7458) 800. [710.5307, 889.5459]70
## # … with 150 more rows, and 1 more variable: `95%` <hilo>Il existe également une représentation automatique du fable via autoplot:
forecast_fable %>%
autoplot(tourism_melb, level = c(50, 95))## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf
## Warning in max(ids, na.rm = TRUE): no non-missing arguments to max; returning
## -Inf## Warning: Removed 80 row(s) containing missing values (geom_path).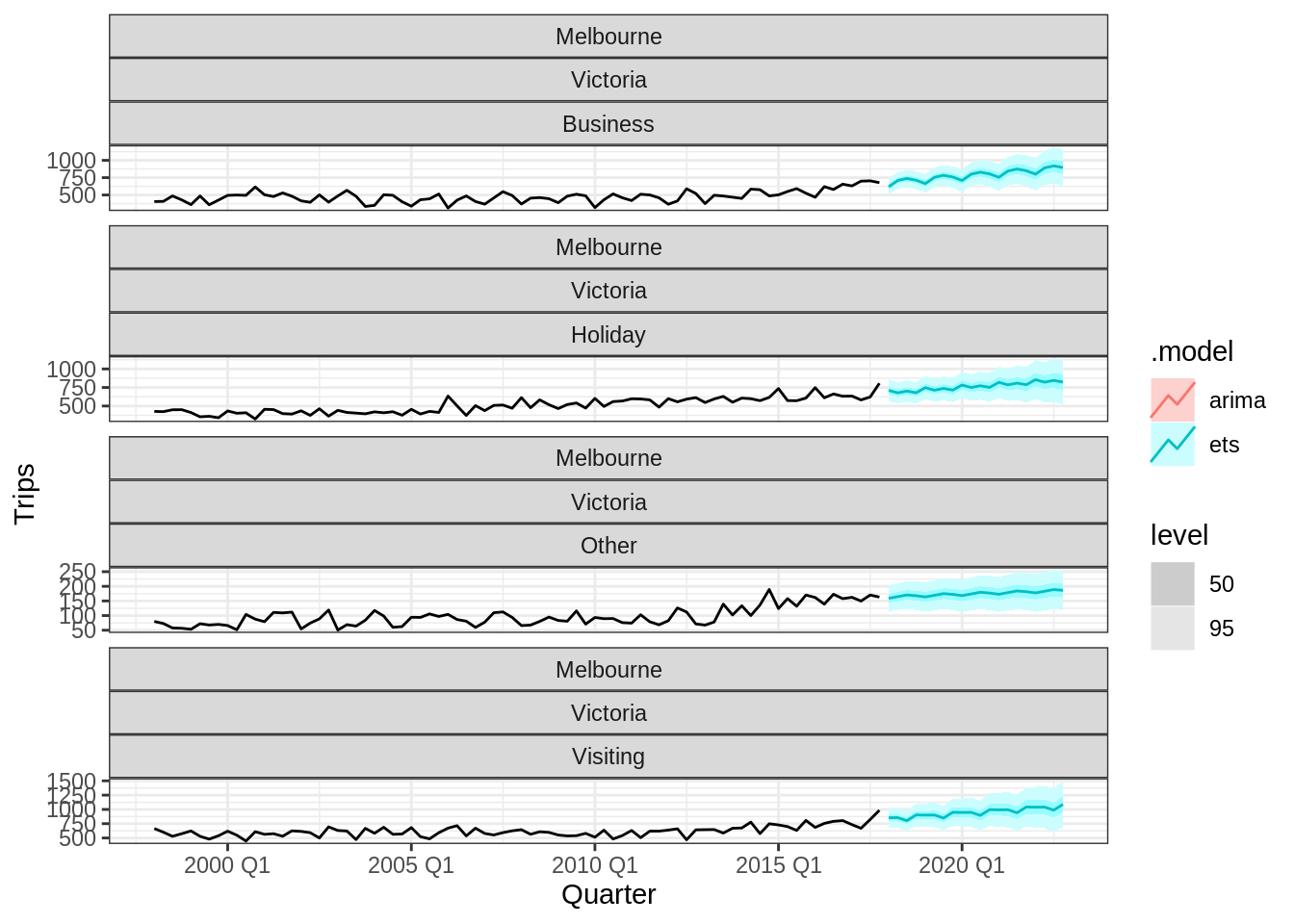
Jeton de reproductilité
sessionInfo()## R version 3.6.3 (2020-02-29)
## Platform: x86_64-conda_cos6-linux-gnu (64-bit)
## Running under: Ubuntu 18.04.5 LTS
##
## Matrix products: default
## BLAS/LAPACK: /usr/share/miniconda/envs/finistR2020/lib/libopenblasp-r0.3.10.so
##
## locale:
## [1] LC_CTYPE=C.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=C.UTF-8 LC_COLLATE=C.UTF-8
## [5] LC_MONETARY=C.UTF-8 LC_MESSAGES=C.UTF-8
## [7] LC_PAPER=C.UTF-8 LC_NAME=C.UTF-8
## [9] LC_ADDRESS=C.UTF-8 LC_TELEPHONE=C.UTF-8
## [11] LC_MEASUREMENT=C.UTF-8 LC_IDENTIFICATION=C.UTF-8
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] slider_0.1.5 fable_0.2.1 fabletools_0.2.1
## [4] tsibble_0.9.2 vip_0.2.2 skimr_2.1.2
## [7] yardstick_0.0.7 workflows_0.1.3 tune_0.1.1
## [10] rsample_0.0.7 recipes_0.1.13 parsnip_0.1.3
## [13] modeldata_0.0.2 infer_0.5.3 dials_0.0.8
## [16] scales_1.1.1 broom_0.7.0 tidymodels_0.1.1
## [19] MASS_7.3-52 mgcv_1.8-33 nlme_3.1-149
## [22] fda_5.1.5.1 Matrix_1.2-18 deSolve_1.28
## [25] GGally_2.0.0 ggdist_2.2.0 distributional_0.2.0
## [28] DT_0.15 forcats_0.5.0 stringr_1.4.0
## [31] dplyr_1.0.2 purrr_0.3.4 readr_1.3.1
## [34] tidyr_1.1.2 tibble_3.0.3 ggplot2_3.3.2
## [37] tidyverse_1.3.0
##
## loaded via a namespace (and not attached):
## [1] readxl_1.3.1 backports_1.1.9 plyr_1.8.6
## [4] repr_1.1.0 lazyeval_0.2.2 splines_3.6.3
## [7] crosstalk_1.1.0.1 listenv_0.8.0 digest_0.6.25
## [10] JuliaCall_0.17.1.9000 foreach_1.5.0 htmltools_0.5.0.9000
## [13] fansi_0.4.1 magrittr_1.5 globals_0.12.5
## [16] modelr_0.1.8 gower_0.2.2 hardhat_0.1.4
## [19] anytime_0.3.9 prettyunits_1.1.1 jpeg_0.1-8.1
## [22] colorspace_1.4-1 blob_1.2.1 rvest_0.3.6
## [25] warp_0.1.0 haven_2.3.1 xfun_0.16
## [28] crayon_1.3.4 jsonlite_1.7.1 progressr_0.6.0
## [31] survival_3.2-3 iterators_1.0.12 glue_1.4.2
## [34] gtable_0.3.0 ipred_0.9-9 DBI_1.1.0
## [37] Rcpp_1.0.5 viridisLite_0.3.0 GPfit_1.0-8
## [40] lava_1.6.7 prodlim_2019.11.13 htmlwidgets_1.5.1
## [43] httr_1.4.2 RColorBrewer_1.1-2 ellipsis_0.3.1
## [46] pkgconfig_2.0.3 reshape_0.8.8 farver_2.0.3
## [49] nnet_7.3-14 dbplyr_1.4.4 utf8_1.1.4
## [52] tidyselect_1.1.0 labeling_0.3 rlang_0.4.7
## [55] DiceDesign_1.8-1 munsell_0.5.0 cellranger_1.1.0
## [58] tools_3.6.3 cli_2.0.2 generics_0.0.2
## [61] ranger_0.12.1 evaluate_0.14 yaml_2.2.1
## [64] knitr_1.29 fs_1.5.0 future_1.18.0
## [67] xml2_1.3.2 compiler_3.6.3 rstudioapi_0.11
## [70] plotly_4.9.2.1 png_0.1-7 reprex_0.3.0
## [73] lhs_1.0.2 stringi_1.4.6 highr_0.8
## [76] lattice_0.20-41 readODS_1.7.0 vctrs_0.3.4
## [79] diffeqr_1.0.0 nycflights13_1.0.1 pillar_1.4.6
## [82] lifecycle_0.2.0 furrr_0.1.0 data.table_1.12.8
## [85] R6_2.4.1 gridExtra_2.3 codetools_0.2-16
## [88] assertthat_0.2.1 withr_2.2.0 parallel_3.6.3
## [91] hms_0.5.3 grid_3.6.3 rpart_4.1-15
## [94] timeDate_3043.102 class_7.3-17 rmarkdown_2.3
## [97] pROC_1.16.2 lubridate_1.7.9 base64enc_0.1-3