OpenMP avec Rcpp
Pierre Navaro
8/24/2021
OpenMP
- OpenMP (Open Multi-Processing) est une bibliothèque permettant de paralléliser des programmes écrits en C++, C, ou Fortran pour Linux, MacOS, et Windows.
- Le code est parallélisé à l’aide d’instructions qui seront interprétées comme des commentaires si la bibliothèque OpenMP n’est pas installée ou si l’option n’est pas présente lors de la compilation.
- OpenMP est utilisable avec R lorsque l’on utilise des fonctions Rcpp. Cette parallélisation peut se révéler particulièrement efficace sur les machines parallèles à mémoire partagée avec des processeurs contenant un grand nombre de coeurs.

Premier exemple
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::plugins(openmp)]]
// [[Rcpp::export(welcome)]]
int welcome(int ncores)
{
#pragma omp parallel num_threads(ncores)
{
Rprintf("Degemer mat! \n");
}
return 0;
}welcome(1)## Degemer mat!## [1] 0welcome(2)## Degemer mat!
## Degemer mat!## [1] 0Addition de deux vecteurs
#include <unistd.h>
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export(slow_add)]]
int slow_add(NumericVector a, NumericVector b, double sec)
{
int n = a.size();
if(n != b.size()) {
throw std::invalid_argument("Two vectors are not of the same length!");
}
NumericVector c(n);
for(size_t i = 0; i < n; i++)
{
sleep(sec);
c(i) = a(i) + b(i);
}
return sum(c);
}Exécution :
a <- 1:8
b <- 1:8
system.time(print(slow_add(a, b, 1)))[3]## [1] 72## elapsed
## 8.002Parallélisation avec OpenMP
#include <unistd.h>
#include <Rcpp.h>
#include <omp.h>
using namespace Rcpp;
// [[Rcpp::plugins(openmp)]]
// [[Rcpp::export(omp_add)]]
int omp_add(NumericVector a, NumericVector b, double sec, int ncores)
{
int n = a.size();
if(n != b.size()) {
throw std::invalid_argument("Two vectors are not of the same length!");
}
NumericVector c(n);
#pragma omp parallel num_threads(ncores)
{
printf("Hello from thread %d of %d \n", omp_get_thread_num(), omp_get_num_threads());
#pragma omp for
for(size_t i = 0; i < n; i++)
{
sleep(sec);
c(i) = a(i) + b(i);
}
}
return sum(c);
}- Test avec 2 threads:
system.time(print(omp_add(a, b, 1, 2)))[3]## [1] 72## elapsed
## 4.001- Test avec 4 threads:
system.time(print(omp_add(a, b, 1, 4)))[3]## [1] 72## elapsed
## 2.002Calcul d’un histogramme
A partir d’un ensemble d’échantillons répartis sur un intervalle (xmin, xmax), nous allons réperer la position de l’échantillon et augmenter l’indice le plus proche de la valeur 1 divisé par le nombre total d’échantillons.
#include <Rcpp.h>
using namespace Rcpp;
using namespace std;
// [[Rcpp::export]]
NumericVector serial_histogram(NumericVector xp) {
double xmin = -7;
double xmax = 7;
int nx = 64;
int np = xp.length();
int ip;
NumericVector rho(nx);
for( int i=0; i < np; ++i) {
double x_norm = (xp[i]-xmin) / (xmax - xmin);
ip = floor(x_norm * nx);
rho[ip] += 1.0 / np;
}
return rho;
}sample <- rnorm(10^3)
rho_serial <- serial_histogram(sample)
plot(seq(-7,7,length.out=64), rho_serial, type = "l", col="blue")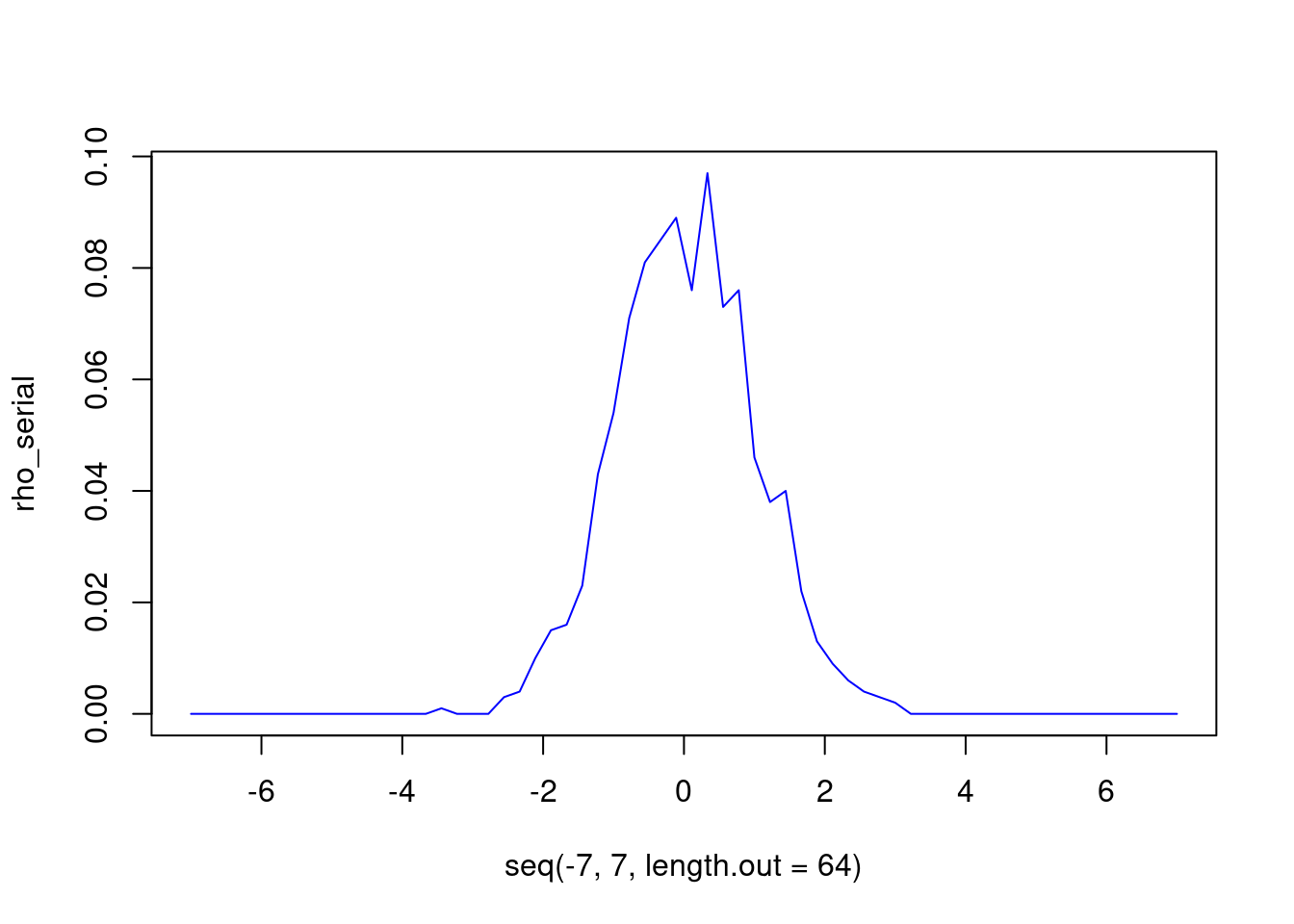
#include <Rcpp.h>
#include <omp.h>
using namespace Rcpp;
// [[Rcpp::plugins(openmp)]]
// [[Rcpp::export]]
NumericVector parallel_histogram_1( NumericVector xp) {
double xmin = -7;
double xmax = 7;
int nx = 64;
int np = xp.length();
int ip;
NumericVector rho(nx);
#pragma omp parallel num_threads(2)
{
int tid = omp_get_thread_num();
int ntid = omp_get_num_threads();
Rprintf("Hello from thread %d of %d \n", tid, ntid);
#pragma omp for
for(int i=0; i < np; ++i){
double x_norm = (xp[i]-xmin) / (xmax - xmin);
int ip = floor(x_norm * nx);
rho(ip) += 1.0 / np;
}
}
return rho;
}rho_parallel_1 = parallel_histogram_1(sample)## Hello from thread 1 of 2
## Hello from thread 0 of 2plot(seq(-7,7,length.out=64), rho_serial, type = "l", col="blue")
lines(seq(-7,7,length.out=64), rho_parallel_1, col="red")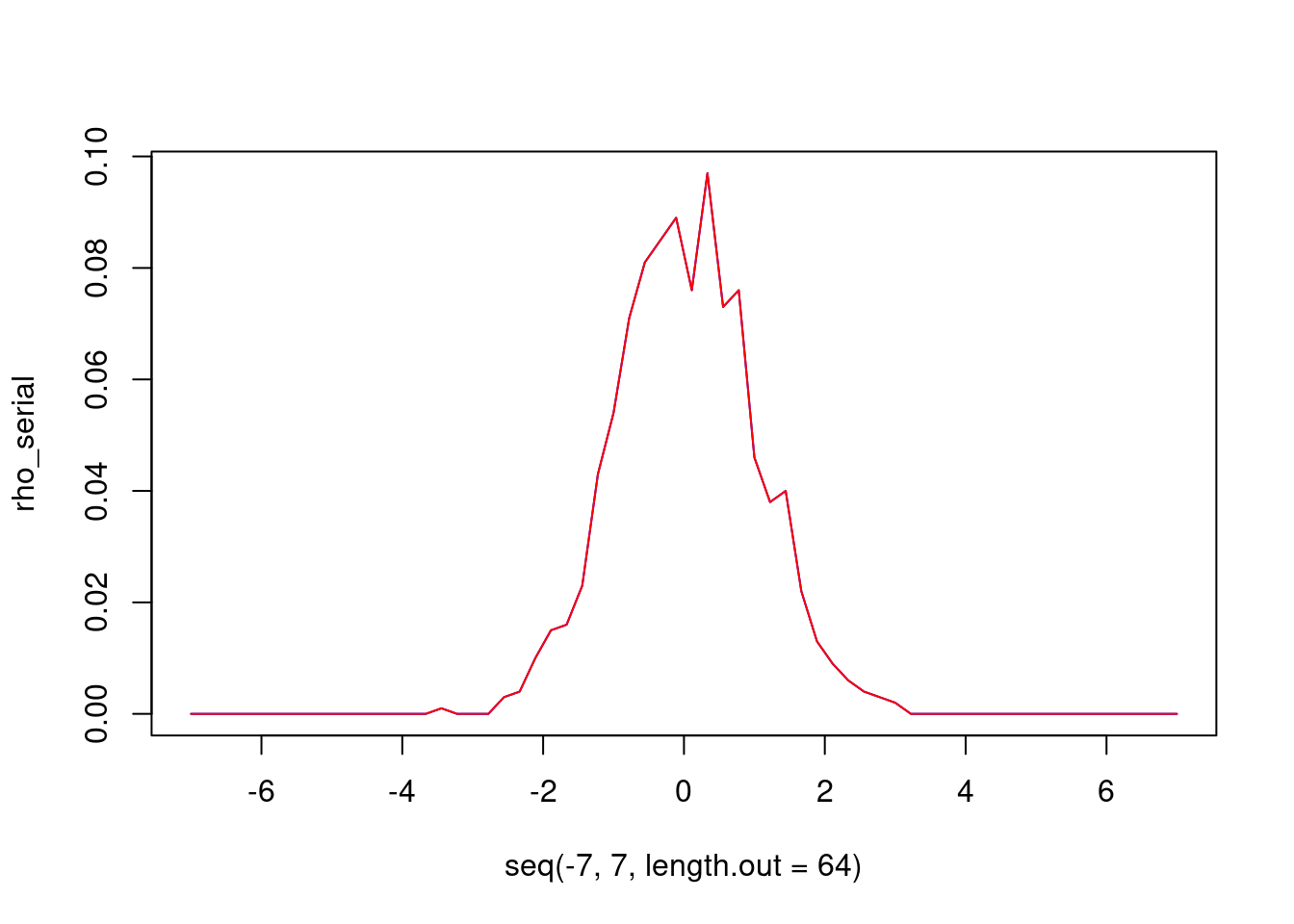
Le résultat n’est pas celui attendu car chaque thread partage le tableau rho et peuvent accéder en même temps aux mêmes indices. Les itérations de la boucle ne sont pas indépendantes.
#include <Rcpp.h>
#include <omp.h>
using namespace Rcpp;
// [[Rcpp::plugins(openmp)]]
// [[Rcpp::export]]
NumericVector parallel_histogram_2( NumericVector xp) {
double xmin = -7;
double xmax = 7;
int nx = 64;
int np = xp.length();
int ip;
NumericVector rho(nx);
int ntid = 2;
NumericMatrix rho_local(ntid,nx);
#pragma omp parallel num_threads(ntid)
{
int tid = omp_get_thread_num();
#pragma omp for
for(int i=0; i < np; ++i){
double x_norm = (xp[i]-xmin) / (xmax - xmin);
int ip = floor(x_norm * nx);
rho_local(tid,ip) += 1.0 / np;
}
#pragma omp master
for (int i = 0; i < nx; ++i) {
double rowSum = 0.0;
for (int j = 0; j < ntid; ++j) {
rowSum += rho_local(j,i);
}
rho(i) += rowSum;
}
}
return rho;
}rho_parallel_2 <- parallel_histogram_2(sample)
plot(seq(-7,7,length.out=64), rho_serial, type = "l", col="blue")
lines(seq(-7,7,length.out=64), rho_parallel_1, col="red")
points(seq(-7,7,length.out=64), rho_parallel_2, col="green")Exercice: estimation du nombre \(pi\)
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
double compute_pi() {
int n = 300000;
double h = 1.0 / n;
double s = 0.0;
for(int i = 0; i < n; ++i)
{
double x = (i - 0.5) * h;
s += 4. / (1 + (x*x));
}
return h * s;
}compute_pi()## [1] 3.141599#includeusing namespace Rcpp; // [[Rcpp::plugins(openmp)]] // [[Rcpp::export]] double compute_pi_omp() { int n = 3000000; double h = 1.0 / n; double s = 0.0; #pragma omp parallel for reduction(+:s) for(int i = 0; i < n; ++i) { double x = (i - 0.5) * h; s += 4. / (1 + (x*x)); } return h * s; }
compute_pi_omp()## [1] 3.141599Conseils
- Minimiser le nombre de régions parallèles.
- Choisir le nombre de threads de telle sorte que le rapport entre le nombre d’instructions et le nombre de directives soit suffisamment grand pour compenser le coût des directives.
- Pour les boucles imbriquées, préférer paralléliser la boucle la plus externe.
- Eviter de paralléliser une boucle trop petite en utilisant la clause if.
- Ajouter des clauses nowait lorsque c’est possible pour éviter des synchronisations inutiles.
Avantages et inconvénients
- OpenMP est beaucoup utilisé en calcul scientifique. C’est une bibliothèque activement développée et est c’est un standard pour la parallélisation en mémoire partagée.
- Dans les dernières versions il y a des instructions spéciales permettant d’utiliser des accélérateurs (GPU).
- L’ouverture d’une zone parallèle ralenti légèrement le code pour allouer de la mémoire supplémentaire. Si l’on l’utilise dan s une fonction Rcpp, elle ne doit pas être appelée un trop grand nombre de fois. Il faut que les calculs situés dans la zone parallèle soit suffisamment importants.
- Il n’y a pas d’incompatibilité avec une parallélisation effectuée au niveau du code R (mcapply).
- Le compilateur par défaut sur les mac ne supporte pas les instructions openmp. Il faut donc les encadrer avec des
#ifdef _OPENMP ... #endif. On peut cependant modifier la variableCXXdans le fichierMakevarspour utiliserg++à la place declang++.